Oval Brief
KI-gestützte Civic-Intelligence-Plattform — 30 Jahre Executive Orders, aufbereitet, durchsuchbar und vernetzt
ovalbrief.comTechnologies Used
Key Features
Das Problem
Executive Orders gehören zu den wirkungsmächtigsten Instrumenten amerikanischer Regierungsführung. Eine einzige Unterschrift kann Handelspolitik umlenken, Bundesbehörden umstrukturieren oder Schutzrechte für Millionen Menschen aufheben. Die verfügbaren Werkzeuge — das Federal Register, WhiteHouse.gov — sind aber für Juristen und Policy-Analysten gebaut, nicht für Bürger.
Ein durchschnittlicher Erlass umfasst 3.000 bis 10.000 Wörter juristischer Fachsprache. Es gibt keine Möglichkeit, Zusammenhänge zwischen Erlassen verschiedener Administrationen zu erkennen. Keine verständlichen Zusammenfassungen. Keine Folgenabschätzung. Keine Antwort auf die Frage: „Was hat sich geändert — und warum ist das wichtig?“
Oval Brief schließt diese Lücke.
Was Oval Brief leistet
Oval Brief ist eine Civic-Intelligence-Plattform, die Executive Orders in zugängliches, vernetztes Wissen transformiert. Abgedeckt werden alle Erlasse von Clinton bis zur aktuellen Administration — über 30 Jahre präsidialer Entscheidungen, verarbeitet und angereichert durch KI.
Für jeden Erlass generiert die Plattform:
- Eine verständliche Zusammenfassung in drei Formaten — Ein-Satz-Headline, Kurz-Abstract und strukturierte Maßnahmen-Aufschlüsselung
- Einen kalibrierten Impact Score auf einer Skala von 1–10, mit expliziter Begründung auf Basis realer Auswirkungen (nicht nur juristischer Reichweite)
- Themenklassifizierung aus einer 27-Themen-Taxonomie in 7 Policy-Clustern — von Handelspolitik bis Weltraumpolitik
- Identifizierung betroffener Gruppen aus 33 Stakeholder-Kategorien in 4 Clustern, mit klarer Unterscheidung zwischen direkter regulatorischer Betroffenheit und beiläufiger Erwähnung
- Querverweise zu verwandten Erlassen — Aufhebungen, Änderungen, Ablösungen, Umsetzungen — automatisch entdeckt durch eine dreiphasige KI-Pipeline
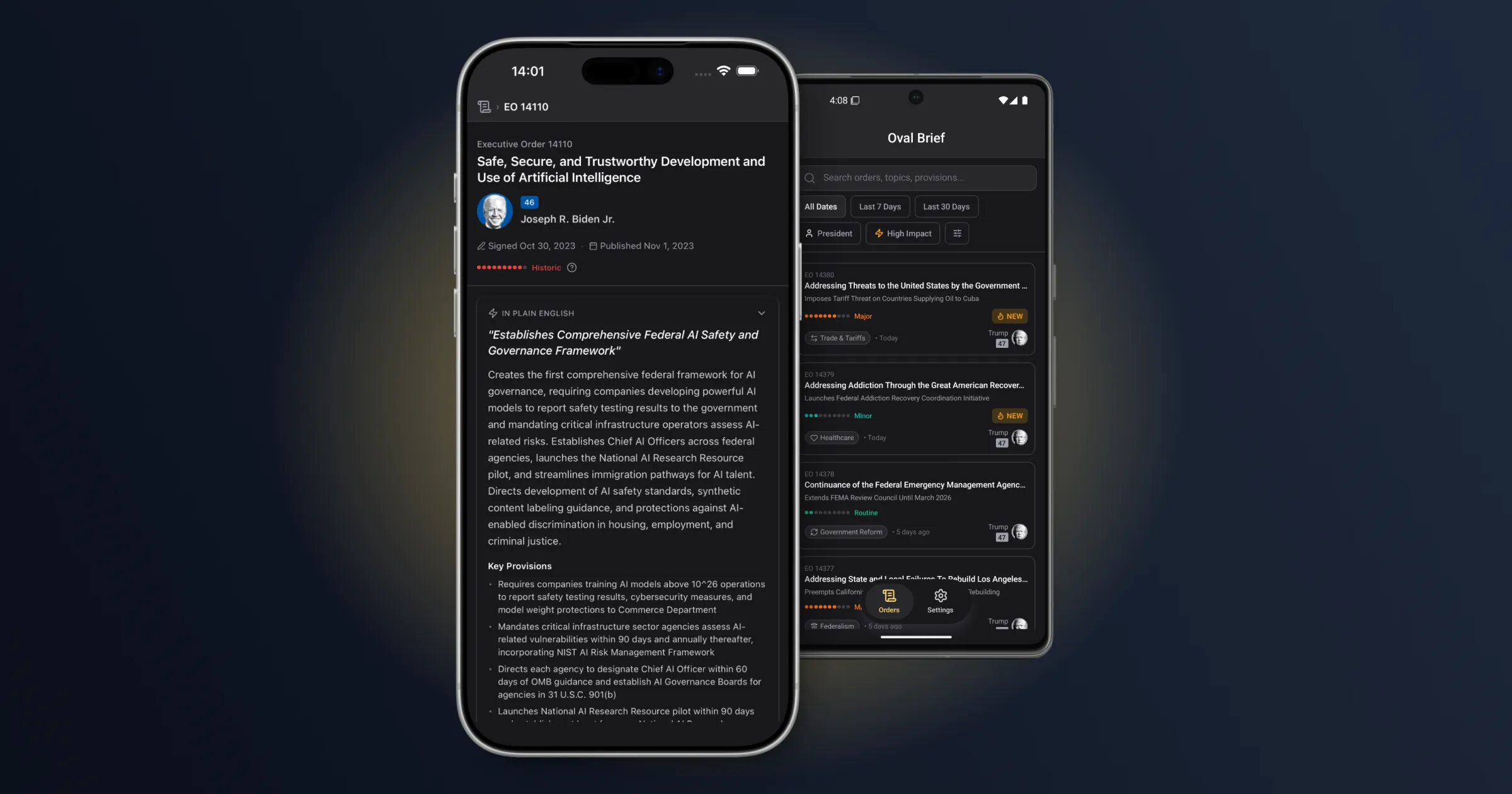
Die Mobile App (React Native/Expo, iOS und Android) ist das primäre Interface. Nutzer durchsuchen einen Endlos-Feed von Executive Orders, jeweils mit farbcodierten Impact-Badges auf einen Blick — von Grün (Routine) bis Rot (Historisch). Ein Tipp auf einen Erlass enthüllt schrittweise tiefere Ebenen: die KI-Zusammenfassung, klassifizierte Themen und betroffene Gruppen, eine Beziehungskarte mit Verbindungen zu anderen Erlassen über Jahrzehnte hinweg, und Links zu den offiziellen Federal-Register-Dokumenten.
Die Filterung ist mehrdimensional — nach Zeitraum, Impact Score, Präsident, Themencluster oder Betroffenengruppe — serverseitig verarbeitet für Performance. Die Designphilosophie: Bloomberg-Terminal trifft Civic-News-App. Datenreich, aber zugänglich.
Die Marketing-Website unter ovalbrief.com läuft auf Astro 5, deployed auf Cloudflare Pages, mit Beta-Anmeldung, Feature-Showcase und Transparenz-Sektion.
Architektur: Die KI-Anreicherungspipeline
Der technische Kern von Oval Brief ist eine Queue-basierte asynchrone Pipeline über sechs Cloudflare Workers, die zwei KI-Services orchestriert, um Rohdaten des Federal Register in strukturierte, vernetzte Inhalte zu transformieren.
Erfassung und Klassifizierung
Die Pipeline beginnt mit der Abfrage der Federal Register API und dem Upsert der Rohdaten in eine Neon-PostgreSQL-Datenbank. Neue Erlasse werden über Cloudflare Queues zur Verarbeitung eingereiht.
Der Processing Worker übernimmt die KI-Analyse. Claude Opus erhält den Volltext jedes Erlasses und liefert in einem Durchlauf: Themenklassifizierung (primär plus bis zu drei sekundäre Themen), Identifizierung betroffener Gruppen mit Begründungsketten, Impact-Scoring mit kalibrierter Einordnung und vier Zusammenfassungsformate. Der Prompt — über mehrere Iterationszyklen verfeinert — erzwingt strikte Klassifizierungsgrenzen, die direkte regulatorische Betroffenheit von beiläufiger Erwähnung unterscheiden.
Nach der Klassifizierung generiert OpenAI 1.536-dimensionale Text-Embeddings aus Headline und Abstract jedes Erlasses — semantisch dichter als die offiziellen Titel, die zu juristischen Standardformulierungen neigen. Diese Embeddings treiben die anschließende Beziehungserkennung.
Dreiphasige Beziehungsextraktion
Hier wird die Architektur interessant. Executive Orders existieren nicht isoliert — sie heben auf, ändern, ersetzen und implementieren sich gegenseitig über Administrationen hinweg. Diese Verbindungen automatisch zu entdecken, ist ein anspruchsvolles Problem.
Phase 1 — Regex-Extraktion. Musterabgleich erfasst explizite Zitate: „Executive Order 13769 vom 27. Januar 2017 wird hiermit aufgehoben.“ Schnell, günstig, aber begrenzt auf Erlasse, die ihre Vorgänger explizit mit Nummer benennen.
Phase 2 — Embedding-Ähnlichkeit. pgvector berechnet die Kosinus-Ähnlichkeit zwischen dem Embedding des neuen Erlasses und allen bestehenden im Korpus. Kandidaten über einem kalibrierten Ähnlichkeitsschwellenwert rücken in Phase 3 vor. Das erfasst thematisch verwandte Erlasse, die einander nicht explizit zitieren — etwa ein Zoll-Erlass von 2025 und eine Handelspolitik-Richtlinie von 2019, die er faktisch ersetzt.
Phase 3 — LLM-Semantische Validierung. Claude Opus prüft jedes Kandidatenpaar und bestimmt den tatsächlichen Beziehungstyp aus 10 Kategorien (revokes, amends, supersedes, supplements, reinstates, extends, implements, references, relates_to und partial revocations). Das Modell validiert und reklassifiziert häufig Regex-gefundene Typen und entdeckt völlig neue Beziehungen, die den ersten beiden Phasen entgehen.
Die drei Phasen ergänzen sich bewusst. Regex ist präzise, aber schmal. Embeddings sind breit, aber verrauscht. LLM-Validierung ist genau, aber teuer. Die Schichtung kontrolliert Kosten bei maximaler Abdeckung.
Infrastruktur
Die gesamte Pipeline läuft auf Cloudflares Edge-Plattform:
- 6 Workers für Fetch, Processing, Enrichment, API-Serving, Dead Letter Queue und Federal-Register-Validierung
- 4 Cloudflare Queues mit dedizierten DLQs für automatische Retries und Fehlerisolierung
- Neon Serverless PostgreSQL mit pgvector-Extension, Drizzle ORM und 30 Migrationen
- KV-Caching auf der API-Ebene für Listen- und Detail-Responses
- Hono + tRPC v11 für durchgängige Type Safety vom Datenbankschema bis zur Mobile App über ein publiziertes npm-Paket
- Terraform für sämtliche Infrastruktur, GitHub Actions mit 5 CI/CD-Workflows
- Apple App Attest + Google Play Integrity zum Schutz der API — die KI-angereicherten Daten sind proprietär
Eine „source is always newer“-Konvention verhindert temporale Unmöglichkeiten in bidirektionalen Beziehungen. Enrichment-Versionierung (v1 für Klassifizierung, v2 für Querverweise) ermöglicht inkrementelle Pipeline-Upgrades ohne vollständige Neuverarbeitung.
Die Prompt-Engineering-Geschichte
Die lehrreichste technische Herausforderung war nicht die Architektur — sondern dem Modell beizubringen, skaliert akkurat zu klassifizieren.
Erste Anreicherungsläufe zeigten eine 31%-Fehlerrate bei der Klassifizierung betroffener Gruppen. Statistische Analyse identifizierte mehrere distinkte Fehlermuster, alle verwurzelt im gleichen Kernproblem: Das Modell interpretierte „erwähnt oder tangential betroffen“ als „betroffen“. Gruppen, die im Text eines Erlasses auftauchten, wurden getaggt, obwohl sie keinen direkten regulatorischen Konsequenzen ausgesetzt waren.
Die Lösung war ein Klassifizierungsgrenzen-Prinzip, direkt im Prompt verankert — das Modell wurde darauf eingeschränkt, direkte regulatorische Betroffenheit von beiläufiger Erwähnung zu unterscheiden. Die richtige Grenzziehung erforderte mehrere Iterationszyklen, jeweils gestützt auf systematische Fehleranalyse über Audit-Batches.
Nach der Verfeinerung sank die klare Fehlerrate auf praktisch null. Ein Golden Dataset aus bewusst schwierigen Erlassen testet Grenzfälle und beziffert die reale Genauigkeit auf 88–92% — wobei die Differenz aus genuinen Ermessensfragen besteht, nicht aus systematischen Fehlern.
Die Zahlen
| Metrik | Wert |
|---|---|
| Verarbeitete Executive Orders | ~1.500 (Clinton bis heute, 1994–Gegenwart) |
| Klassifizierungsfehlerrate | Weniger als 1% klare Fehler; 88–92% bei Stress-Tests |
| Entdeckte Beziehungstypen | 10 Typen über den gesamten Korpus |
| Entwicklungszeitraum | ~5 Wochen Teilzeitarbeit |
| KI-generierter Code | 95%+ via Claude Code |
| Abgeschlossene Linear-Issues | 140 |
| Gemergte Pull Requests | 221 über 3 Repositories |
| Commits gesamt | 962 |
| Datenbank-Migrationen | 30 |
Wie es gebaut wurde
Oval Brief wurde als Solo-Projekt mit strukturierter agentengestützter Entwicklung gebaut — Claude Code für die Implementierung, CodeRabbit für automatisierte PR-Reviews, Linear mit MCP-Integration für Issue-Management. Jede Änderung durchlief einen geprüften Pull Request. Keine direkten Pushes auf Main.
Die Methodik komprimierte einen konventionell 6+ Monate dauernden Entwicklungsaufwand auf 5 Wochen Abend- und Wochenendarbeit. Custom Slash Commands (/impl für Issue-Aufnahme, /ship für den kompletten Git-bis-PR-Workflow) eliminierten den Kontextwechsel-Overhead — entscheidend für ein Nebenprojekt.
Aber die Methodik ist die Nebenstory, nicht die Schlagzeile. Entscheidend ist, was ausgeliefert wurde: eine produktionsreife Civic-Intelligence-Plattform mit einer anspruchsvollen KI-Pipeline, Dual-Plattform-Mobile-Apps, Serverless-Edge-Infrastruktur und 30 Jahren vernetzter Executive-Order-Daten.
Tech Stack
| Ebene | Technologien |
|---|---|
| KI & Daten | Claude Opus, OpenAI Embeddings, pgvector, 3-Phasen-Beziehungspipeline |
| Mobile | React Native 0.81, Expo SDK 54, NativeWind v4, React Query v5 |
| API | Hono, tRPC v11, Cloudflare Workers, KV-Caching |
| Datenbank | Neon Serverless PostgreSQL, Drizzle ORM, 1.536-dim HNSW-Index |
| Infrastruktur | Cloudflare Workers & Queues, Terraform, GitHub Actions |
| Sicherheit | Apple App Attest, Google Play Integrity, JWT Sessions |
| Website | Astro 5, Cloudflare Pages, Tailwind CSS v4 |