Oval Brief
AI-powered civic intelligence platform turning 30 years of executive orders into accessible, searchable, interconnected knowledge
ovalbrief.comTechnologies Used
Key Features
The Problem
Executive orders are among the most consequential instruments of American governance. A single signature can redirect trade policy, restructure federal agencies, or revoke protections affecting millions. Yet the tools available to understand them — the Federal Register, WhiteHouse.gov — are built for lawyers and policy analysts, not citizens.
The raw text averages 3,000–10,000 words of dense legal language. There’s no way to see how orders connect to each other across administrations. No plain-English summaries. No impact assessment. No way to answer “what changed and why does it matter?”
Oval Brief exists to close that gap.
What Oval Brief Does
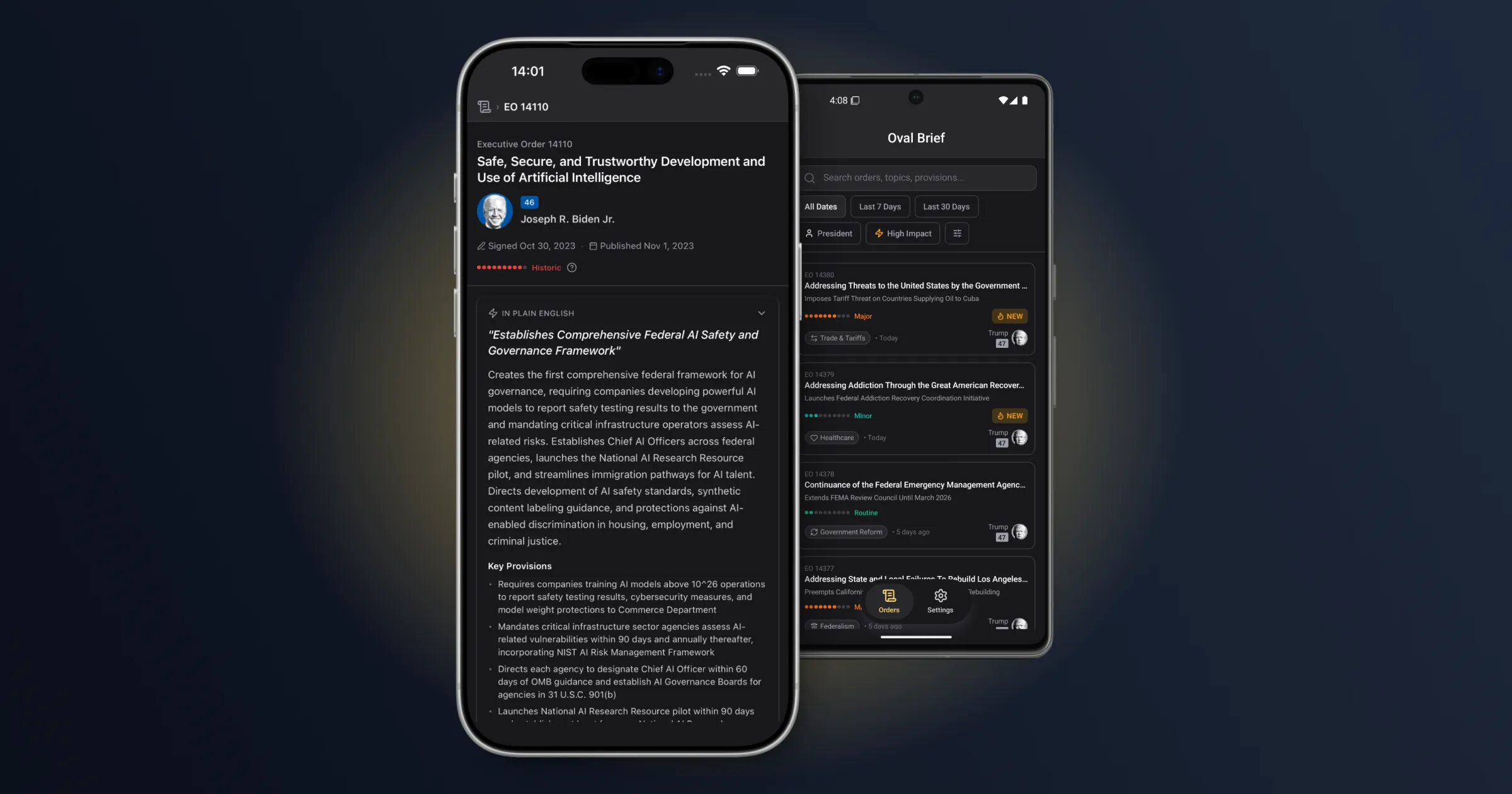
Oval Brief is a civic intelligence platform that transforms raw executive orders into accessible, interconnected knowledge. It covers every executive order from Clinton through the current administration — over 30 years of presidential action, processed and enriched by AI.
For every order, the platform generates:
- A plain-English summary in three formats — a one-sentence headline, a two-to-three sentence abstract, and a structured provisions breakdown
- A calibrated impact score on a 1–10 scale, with explicit justification anchored to real-world consequences (not just legal scope)
- Topic classification drawn from a 27-topic taxonomy organized into 7 policy clusters — from Trade & Tariffs to Space Policy
- Affected group identification across 33 stakeholder groups in 4 clusters, distinguishing direct regulatory impact from incidental mention
- Cross-references to related orders — revocations, amendments, supersessions, implementations — discovered automatically through a three-phase AI pipeline
The mobile app (React Native/Expo, iOS and Android) is the primary interface. Users browse an infinite-scrolling feed of executive orders, each showing impact severity at a glance through color-coded badges ranging from green (Routine) through red (Historic). Tapping into an order reveals progressively deeper layers: the AI summary, classified topics and affected groups, a relationship map showing how the order connects to others across decades, and links to the official Federal Register documents.
Filtering is multi-dimensional — by time range, impact score, president, topic cluster, or affected group cluster — all processed server-side for performance. The design philosophy: Bloomberg terminal meets civic news app. Data-rich, but approachable.
The marketing site at ovalbrief.com runs on Astro 5, deployed to Cloudflare Pages, with beta signup, feature showcase, and trust/transparency sections.
Architecture: The AI Enrichment Pipeline
The technical core of Oval Brief is a queue-based asynchronous pipeline running across six Cloudflare Workers, orchestrating two AI services to transform raw Federal Register data into structured, interconnected content.
Ingestion and Classification
The pipeline starts by polling the Federal Register API and upserting raw order data into a Neon PostgreSQL database. New orders are queued for processing via Cloudflare Queues.
The processing worker handles the heavy AI work. Claude Opus receives each order’s full text and produces a comprehensive analysis in a single pass: topic classification (primary plus up to three secondary topics), affected group identification with reasoning chains, impact scoring with calibrated justification, and four summary formats. The prompt — refined through multiple iteration cycles — enforces strict classification boundaries that distinguish direct regulatory impact from incidental mention.
After classification, OpenAI generates 1,536-dimension text embeddings from each order’s headline and abstract — semantically denser than official titles, which tend toward boilerplate legal language. These embeddings power the relationship discovery that follows.
Three-Phase Relationship Extraction
This is where the architecture gets interesting. Executive orders don’t exist in isolation — they revoke, amend, supersede, and implement each other across administrations. Discovering these connections automatically is a hard problem.
Phase 1 — Regex extraction. Pattern matching catches explicit citations: “Executive Order 13769 of January 27, 2017, is hereby revoked.” Fast, cheap, but limited to orders that explicitly name their predecessors by number.
Phase 2 — Embedding similarity. pgvector computes cosine similarity between the new order’s embedding and every existing order in the corpus. Candidates above a calibrated similarity threshold advance to Phase 3. This catches thematically related orders that don’t explicitly cite each other — like a 2025 tariff order and a 2019 trade policy it effectively replaces.
Phase 3 — LLM semantic validation. Claude Opus examines each candidate pair and determines the actual relationship type from 10 categories (revokes, amends, supersedes, supplements, reinstates, extends, implements, references, relates_to, and partial revocations). The model validates and frequently reclassifies regex-discovered types, and discovers entirely new relationships that the first two phases miss.
The three phases are complementary by design. Regex is precise but narrow. Embeddings are broad but noisy. LLM validation is accurate but expensive. Layering them controls cost while maximizing recall.
Infrastructure
The full pipeline runs on Cloudflare’s edge platform:
- 6 Workers handling fetch, processing, enrichment, API serving, dead letter queue management, and Federal Register API validation
- 4 Cloudflare Queues with dedicated DLQs for automatic retry and failure isolation
- Neon Serverless PostgreSQL with pgvector extension, Drizzle ORM, and 30 migrations tracking schema evolution
- KV caching on the API layer for list and detail responses
- Hono + tRPC v11 providing end-to-end type safety from database to mobile app via a published npm package
- Terraform managing all infrastructure, GitHub Actions running 5 CI/CD workflows
- Apple App Attest + Google Play Integrity protecting the API from scraping — the AI-enriched data is proprietary
A "source is always newer" convention prevents temporal impossibilities in bidirectional relationships. Enrichment versioning (v1 for classification, v2 for cross-references) allows incremental pipeline upgrades without full reprocessing.
The Prompt Engineering Story
The most instructive technical challenge wasn’t architecture — it was teaching the model to classify accurately at scale.
Initial enrichment runs showed a 31% error rate on affected group classification. Statistical analysis revealed several distinct failure patterns, all rooted in the same core issue: the model interpreted “mentioned or tangentially related” as “affected.” Groups that appeared in an order’s text were being tagged even when they faced no direct regulatory consequences.
The fix was a classification boundary principle embedded directly in the prompt — constraining the model to distinguish direct regulatory impact from incidental mention. Getting that boundary right required multiple iteration cycles, each informed by systematic error analysis across audit batches.
After refinement, the clear error rate dropped to effectively zero. A golden dataset of deliberately challenging orders stress-tests edge cases and puts real accuracy at 88–92% — with the gap consisting of genuinely ambiguous judgment calls, not systematic failures.
The Numbers
| Metric | Value |
|---|---|
| Executive orders processed | ~1,500 (Clinton through current, 1994–present) |
| Classification error rate | Less than 1% clear errors; 88–92% on stress-tested edge cases |
| Relationship types discovered | 10 types across the full corpus |
| Development timeline | ~5 weeks of part-time work |
| AI-generated code | 95%+ via Claude Code |
| Linear issues completed | 140 |
| Pull requests merged | 221 across 3 repositories |
| Total commits | 962 |
| Database migrations | 30 |
How It Was Built
Oval Brief was built solo using structured agentic development — Claude Code for implementation, CodeRabbit for automated PR review, Linear with MCP integration for issue management. Every change went through a reviewed pull request. No direct pushes to main.
The methodology compressed what would conventionally be a 6+ month development effort into 5 weeks of evening and weekend work. Custom slash commands (/impl for issue pickup, /ship for the full git-to-PR workflow) eliminated context-switching overhead, making progress possible in small increments — critical for a side project.
But the methodology is the supporting story, not the headline. What matters is what got shipped: a production-grade civic intelligence platform with a sophisticated AI pipeline, dual-platform mobile apps, serverless edge infrastructure, and 30 years of interconnected executive order data.
Tech Stack
| Layer | Technologies |
|---|---|
| AI & Data | Claude Opus, OpenAI Embeddings, pgvector, 3-phase relationship pipeline |
| Mobile | React Native 0.81, Expo SDK 54, NativeWind v4, React Query v5 |
| API | Hono, tRPC v11, Cloudflare Workers, KV caching |
| Database | Neon Serverless PostgreSQL, Drizzle ORM, 1,536-dim HNSW index |
| Infrastructure | Cloudflare Workers & Queues, Terraform, GitHub Actions |
| Security | Apple App Attest, Google Play Integrity, JWT sessions |
| Website | Astro 5, Cloudflare Pages, Tailwind CSS v4 |